README
![]()
This is the official codebase of the dataset paper GLOBEM Dataset: Multi-Year Datasets for Longitudinal Human Behavior Modeling Generalization, accepted by NeurIPS 2022 Dataset and Benchmark Track (Link)
This is the official codebase of the platform paper GLOBEM: Cross-Dataset Generalization of Longitudinal Human Behavior Modeling, accepted by IMWUT 2023 (Link) 🏆 Our paper has won the Distinguished Paper Award @ UbiComp 2023!
Introduction
GLOBEM is a platform to accelerate cross-dataset generalization research in the longitudinal behavior modeling domain. The name GLOBEM is the short for Generalization of LOngitudinal BEhavior Modeling.
GLOBEM not only supports flexible and rapid evaluation of the existing behavior modeling methods, but also provides easy-to-extend templates for researchers to develop and prototype their own behavior modeling algorithms.
GLOBEM currently supports depression detection and closely reimplements the following algorithms1:
-
Traditional Machine Learning Algorithm
- Trajectories of depression: Unobtrusive monitoring of depressive states by means of smartphone mobility traces analysis, by Canzian et al., 2015
- Mobile phone sensor correlates of depressive symptom severity in daily-life behavior: An exploratory study, by Saeb et al., 2015
- Behavior vs. introspection: refining prediction of clinical depression via smartphone sensing data, by Farhan et al., 2016
- Mobile Sensing and Support for People With Depression: A Pilot Trial in the Wild, by Wahle et al., 2016
- Joint Modeling of Heterogeneous Sensing Data for Depression Assessment via Multi-task Learning, by Lu et al., 2018
- Tracking Depression Dynamics in College Students Using Mobile Phone and Wearable Sensing, by Wang et al., 2018
- Leveraging Routine Behavior and Contextually-Filtered Features for Depression Detection among College Students, by Xu et al., 2019
- Leveraging Collaborative-Filtering for Personalized Behavior Modeling: A Case Study of Depression Detection among College Students, by Xu et al., 2021
- Detecting Depression and Predicting its Onset Using Longitudinal Symptoms Captured by Passive Sensing, by Chikersal et al., 2021
-
Deep Learning Based Domain Generalization Algorithm
- Empirical Risk Minimization (ERM)
- Data Manipulation
- Mixup, by Zhang et al., 2018
- Representation Learning
- Domain-Adversarial Neural Network (DANN), by Ganin et al., 2017
- Invariant Risk Minimization (IRM), by Arjovsky et al., 2020
- Common Specific Decomposition (CSD), by Piratla et al., 2020
- Learning Strategy
- Meta-Learning for Domain Generalization (MLDG), by Li et al., 2017
- Model-Agnostic Learning of Semantic Features (MASF), by Dou et al., 2019
- Siamese Network, by Koch et al., 2015
- Reorder, by Xu et al., 2022
Highlight
Multi-year Dataset (README.md)
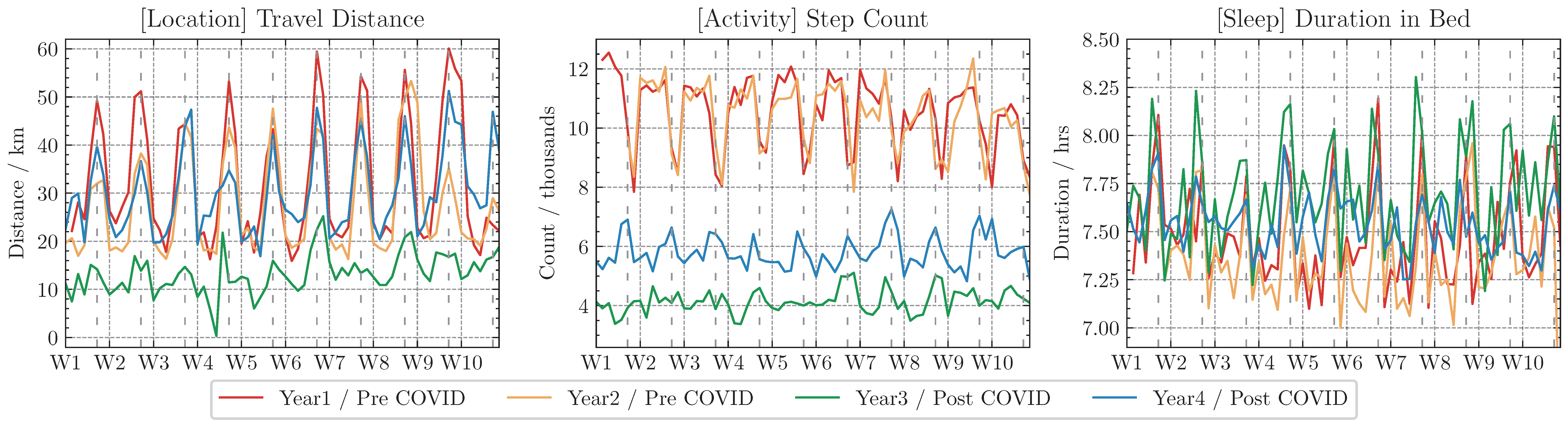
Along with the GLOBEM, we released the frist multi-year mobile and wearable sensing datasets that contain four data collection studies from 2018 to 2021, covering over 700 person-years from 497 unique users. To download the dataset, please visit our PhysioNet page, and data_raw/README.md for more details about data format.
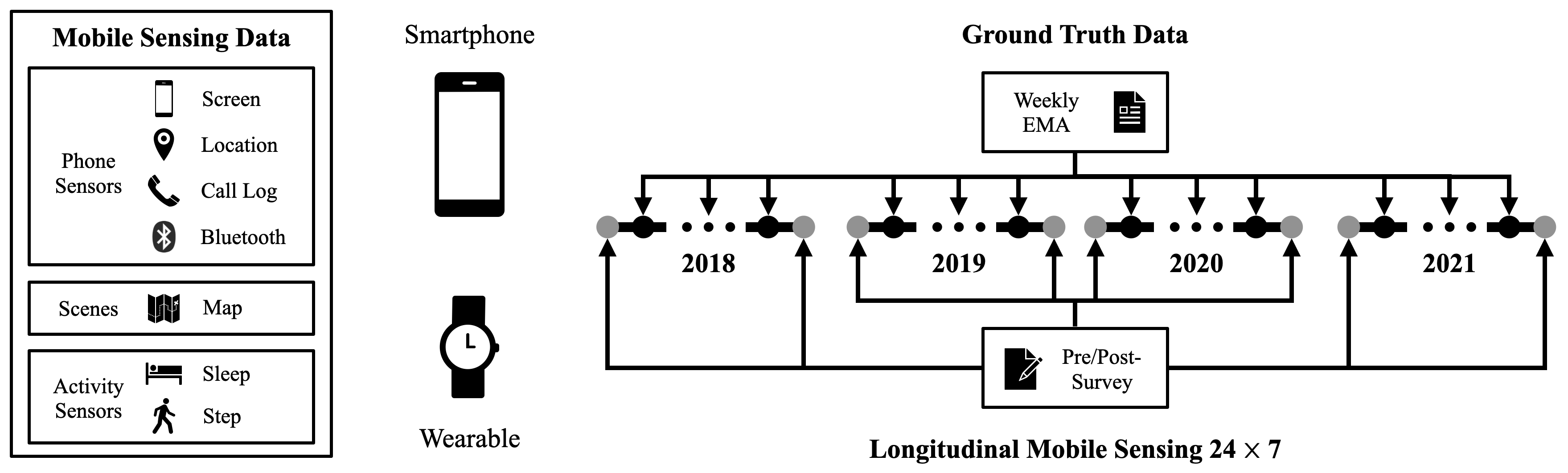
The datasets capture various aspects of participants' life experience:
Benchmark
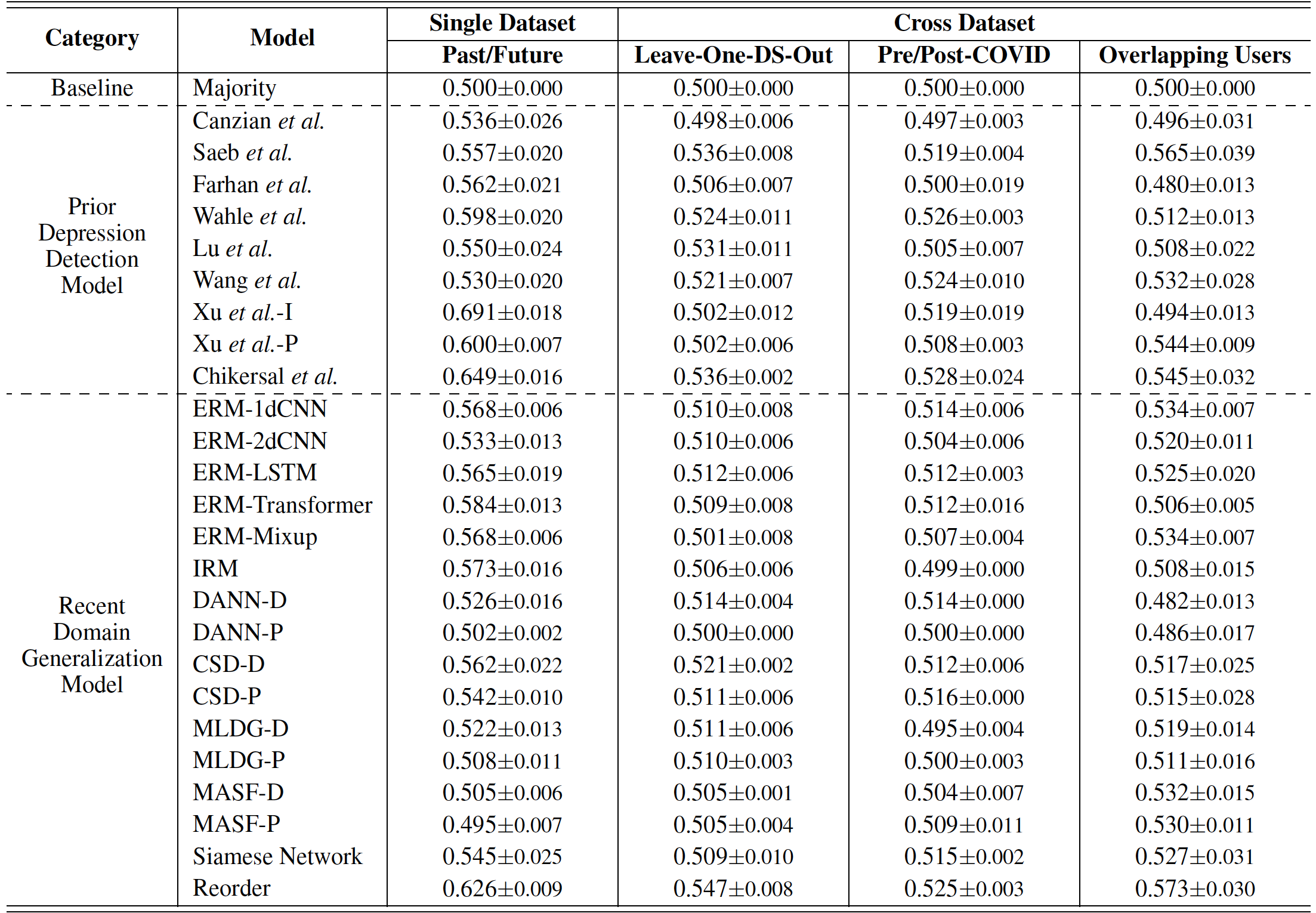
The table shows the balanced accuracy performance of different algorithms in multiple evaluation setups:
Tutorial
Below is a brief description of the platform and a simple tutorial on how to use the platform. This tutorial uses depression detection as the longitudinal behavior modeling example.
TL;DR
Our platform is tested with Python 3.7 under MacOS 11.6 (intel) and CentOS 7. Try the platform with one line of command, assuming Anaconda/miniconda is already installed on the machine. Please find the details of the setup and examples explained in the rest of tutorial.
/bin/bash run.sh
Setup
Environment
GLOBEm is a python-based platform to leverage its flexibility and large number of open libraries. Java JDK (>= 11) is needed for ml_xu_interpretable, ml_xu_personalized, and ml_chikersal. Here is an example of using Anaconda or miniconda for environment setup:
conda create -n globem python=3.7
conda activate globem
pip install -r requirements.txt
Dataset Preparation
Example raw data are provided in data_raw folder2. Each dataset contains ParticipantsInfoData, FeatureData, and SurveyData. Please refer to data_raw/README.md for more details about the raw data format.
A simple script is prepared to process these raw data and save a list of files into data folder. As different subjects may have a different amount of data, the main purpose of the processing is to slice the data into standard <feature matrix, label> pairs (see Input for the definitions). Every dataset contains a list of <feature matrix, label> pairs, which are saved in a DatasetDict object.
The preparation can be done by running (ETA ~45 mins with the completed version of the four-year dataset, ~3 mins with the sample data.)
python data/data_prep.py
How to run an existing algorithm
The template command:
python evaluation/model_train_eval.py
--config_name=[a model config file name]
--pred_target=[prediction target]
--eval_task=[evaluation task]
Currently, pred_target supports the depression detection task:
dep_weekly: weekly depression status prediction
eval_task supports a few single or multiple evaluation setups, such as:
single_within_user: within-user training/testing on a single datasetallbutone: leave-one-dataset-out setupcrosscovid: pre/post COVID setup, only support certain datasetstwo_overlap: train/test on overlapping users between two datasetsall: do all evaluation setups
An example of running Chikersal et al.'s algorithm on each dataset to predict weekly depression:
python evaluation/model_train_eval.py \
--config_name=ml_chikersal \
--pred_target=dep_weekly \
--eval_task=single_within_user
An example of running Reorder algorithm with a leave-one-dataset-out setup to predict weekly depression (Note that deep learning algorithms are not compatible with the end-of-term prediction task due to the limited data size):
python evaluation/model_train_eval.py \
--config_name=dl_reorder \
--pred_target=dep_weekly \
--eval_task=allbutone
The model training and evaluation results will be saved at evaluation_output folder with corresponding path.
In these two examples, they will be saved at evaluation_output/evaluation_single_dataset_within_user/dep_weekly/ml_chikersal.pkl and evaluation_output/evaluation_allbutone_datasets/dep_weekly/dl_reoreder.pkl, respectively.
Reading the results is straightforward:
import pickle
import pandas, numpy
with open("evaluation_output/evaluation_single_dataset_within_user/dep_weekly/ml_chikersal.pkl", "rb") as f:
evaluation_results = pickle.load(f)
df = pandas.DataFrame(evaluation_results["results_repo"]["dep_weekly"]).T
print(df[["test_balanced_acc", "test_roc_auc"]])
with open("evaluation_output/evaluation_allbutone_datasets/dep_weekly/dl_reorder.pkl", "rb") as f:
evaluation_results = pickle.load(f)
df = pandas.DataFrame(evaluation_results["results_repo"]["dep_weekly"]).T
print(df[["test_balanced_acc", "test_roc_auc"]])
Please refer to analysis/prediction_results_analysis.ipynb for more examples of results processing.
Code Breakdown
The two examples above are equivalent to the following code blocks:
Chikersal et al.'s algorithm doing the single dataset evaluation task:
import pandas, numpy
from data_loader import data_loader_ml
from utils import train_eval_pipeline
from algorithm import algorithm_factory
ds_keys = ["INS-W_1", "INS-W_2", "INS-W_3", "INS-W_4"] # list of datasets to be included
pred_targets = ["dep_weekly"] # list of prediction task
config_name = "ml_chikersal" # model config
dataset_dict = data_loader_ml.data_loader(ds_keys_dict={pt: ds_keys for pt in pred_targets})
algorithm = algorithm_factory.load_algorithm(config_name=config_name)
evaluation_results = train_eval_pipeline.single_dataset_within_user_driver(
dataset_dict, pred_targets, ds_keys, algorithm, verbose=0)
df = pandas.DataFrame(evaluation_results["results_repo"][pred_targets[0]]).T
print(df[["test_balanced_acc", "test_roc_auc"]])
| Model | Balanced Accuracy | ROC AUC | ||||||
| INS-1 | INS-2 | INS-3 | INS-4 | INS-1 | INS-2 | INS-3 | INS-4 | |
| Chikersal et al. | 0.656 | 0.611 | 0.641 | 0.690 | 0.726 | 0.679 | 0.695 | 0.763 |
Reorder algorithm doing the leave-one-dataset-out generalization task:
import pandas
from data_loader import data_loader_dl
from utils import train_eval_pipeline
from algorithm import algorithm_factory
ds_keys = ["INS-W_1", "INS-W_2", "INS-W_3", "INS-W_4"] # list of datasets to be included
pred_targets = ["dep_weekly"] # list of prediction task
config_name = "dl_reorder" # model config
dataset_dict = data_loader_dl.data_loader_dl_placeholder(pred_targets, ds_keys)
algorithm = algorithm_factory.load_algorithm(config_name=config_name)
evaluation_results = train_eval_pipeline.allbutone_datasets_driver(
dataset_dict, pred_targets, ds_keys, algorithm, verbose=0)
df = pandas.DataFrame(evaluation_results["results_repo"][pred_targets[0]]).T
print(df[["test_balanced_acc", "test_roc_auc"]])
| Model | Balanced Accuracy | ROC AUC | ||||||
| INS-1 | INS-2 | INS-3 | INS-4 | INS-1 | INS-2 | INS-3 | INS-4 | |
| Reorder | 0.548 | 0.542 | 0.530 | 0.568 | 0.567 | 0.564 | 0.552 | 0.571 |
There are also some additional evaluation parameters that can be set through config files. Please refer to config/README.md.
Some intermediate files may be saved in tmp folder to accelerate repeated testing (tmp folder also includes some example code and auxiliary materials). The evaluation results will be saved as a pkl file in evaluation_output at the corresponding path.
From sample data to full data
By default, the platform is running on sample data from the datasets.
To switch to the full data, please follow the following simple steps:
- Access and download the completed data from the PhysioNet page.
- Unzip the downloaded data and put the datasets (each one is a unique folder) into
data_raw. Please refer todata_raw/README.mdfor more dataset details. - Go to
config/global_config.pyto setglobal_config["all"]["ds_keys"]by commentingline7and uncommentingline6.
Platform Description
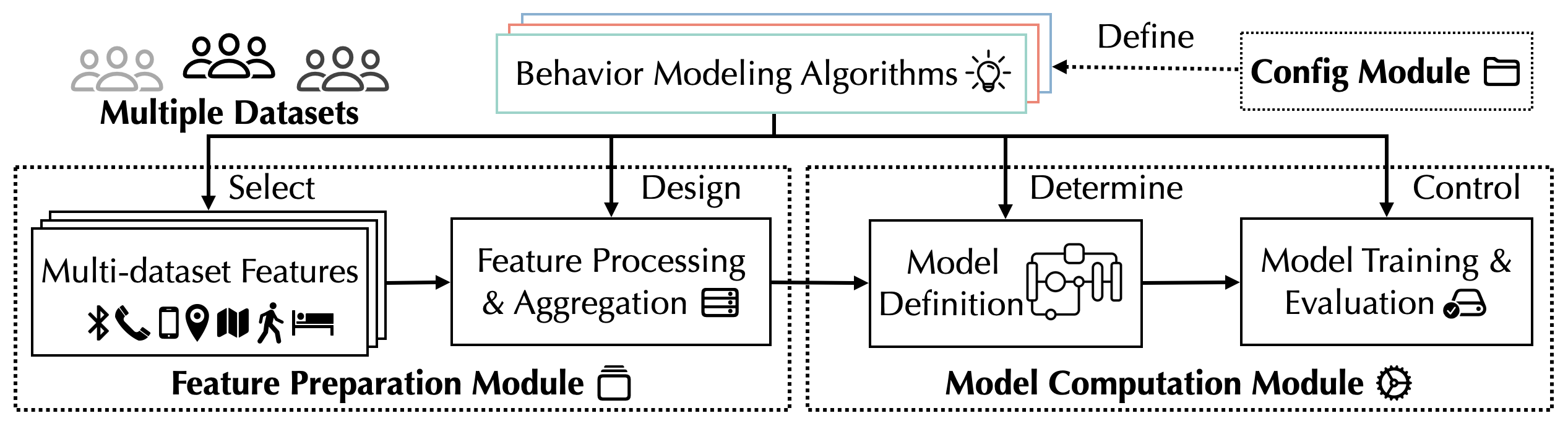
GLOBEM provides three major modules and a few utility functions:
- Feature Preparation Module
- Model Computatoin Module
- Configuration Module
Each algorithm (DepressionDetectionAlgorithmBase defined in algorithm/base.py) consists of these three modules to form a complete pipeline that leads to one (or more) machine learning models: from feature preparation (as model input) to model computation (to obtain model output), with parameters controlled by the configuration module.
Input
After dataset preparation (as explained in Dataset Preparation section), an initial input data point will be a standard <feature matrix, label> pair.
label: the ground truth (currently, it is a binary label) indicating a subject's self-report depressive symptom status on a certain date.
feature matrix: given the date of the label, the feature matrix includes daily feature vectors in the past four weeks, with the dimension as (28, # of features).
Feature Preparation Module
This module defines the features used by the algorithm as the input. The function DepressionDetectionAlgorithmBase.prep_data_repo determines this process of an algorithm.
For traditional machine learning algorithms, this can be basic feature selection, aggregation, and filtering (e.g., mean, std) along the feature matrix's temporal dimension (e.g., Canzian et al., Saeb et al.), or complex feature extraction (e.g., Xu et al., Chikersal et al.).
For deep learning algorithms, this is a definition of a feature data feeding process (i.e., a data generator) that prepares data for deep model training (e.g., ERM).
Model Computation Module
This module defines the model construction and training process. The function DepressionDetectionAlgorithmBase.prep_model determines a prediction model generated by the algorithm. The prep_model function will return a DepressionDetectionClassifierBase object that specifies the model design, training, and prediction process.
For traditional machine learning algorithms, this can be some off-the-shelf model such as an SVM (e.g., Farhan et al.), or some customized statistical model (e.g., Lu et al.) that is ready to be trained with input data.
For deep learning algorithms, this is a definition of deep modeling architecture and training process (e.g., IRM), and builds a deep model that is ready to be trained with input data.
Multiple Models from One Algorithm
It is worth noting that one algorithm can define multiple models. For example, ERM can use different deep learning architectures such as ERM-1D-CNN, ERM-2D-CNN, ERM-Transformer; DANN can take each dataset as a domain (DANN-dataset as domain), or each person as a domain (DANN-person as domain).
Configuration Module
This module provides the flexibility of controlling different parameters in the Feature Preparation Module and Model Computation Module. Each algorithm has its own unique parameters that can be added to this module.
The platform employs a simple yaml file system. Each model (NOT algorithm) has its own unique config yaml file in config folder with a unique file name. For example, Chikersal et al. can have one model, and its config file is config/ml_chikersal.yaml; DANN can have two models, so it has two config files: config/dl_dann_ds_as_domain.yaml and config/dl_dann_person_as_domain.yaml, respectively.
Extending the Platform
How to add a new algorithm
The platform supports researchers in developing their own algorithms easily. Reading through Platform Description before implementing new algorithms is highly recommended.
An algorithm just needs to extend the abstract class DepressionDetectionAlgorithmBase and implement:
- Define the function
prep_data_repo(as the feature preparation module) It takes inDatasetDictas the input and returns aDataRepoobject (see here), which is a simple data object that savesX,y, andpids(participant ids). This can be used for preparing both training and testing sets. - Define the function
prep_model(as the model computation module) It returns aDepressionDetectionClassifierBaseobject (see here), which needs to supportfit(model training),predict(model prediction), andpredict_proba(model prediction with probability distribution). - Add a configuration file in
config(as the configuration module) At least one yaml file with a unique name needs to be put in theconfigfolder. The config file will contain controllable parameters that can be adjusted manually. Please refer toconfig/README.mdfor more details. - Register the new algorithm in
algorithm/algorithm_factory.pyby adding appropriate class import and if-else logic.
How to add a traditional machine learning algorithm
We provide a basic traditional machine learning algorithm DepressionDetectionAlgorithm_ML_basic that extends DepressionDetectionAlgorithmBase.
Its prep_data_repo function 1. takes the feature vector at the same day of the collected label, 2. performs a feature normalization, 3. filters empty features and days with a large amount of missing data, 4. imputes the rest of the missing data using median, 5. puts the data into a DataRepo and return it.
Its prep_model function is left empty for custom implementation.
This object can serve as a starting point and other traditional ML algorithms can extend DepressionDetectionAlgorithm_ML_basic. For example, the implementation of Saeb et al.'s algorithm can be found algorithm/ml_saeb.py and config/ml_saeb.yaml
How to add a deep learning algorithm
We use ERM (algorithm/dl_erm.py) as the basic deep learning algorithm DepressionDetectionAlgorithm_DL_erm that extends DepressionDetectionAlgorithmBase.
Its prep_data_repo function prepares a set of data loaders MultiSourceDataGenerator as training&validation or testing set, puts them into a DataRepo and returns it.
Its prep_model function defines a standard deep-learning classifier DepressionDetectionClassifier_DL_erm that extends DepressionDetectionClassifierBase and defines how a deep model should be trained, saved, and evaluated. The training setup is parameterized in config files such as config/dl_erm_1dCNN.yaml.
This algorithm can serve as a starting point, and other DL algorithms can extend DepressionDetectionAlgorithm_DL_erm and DepressionDetectionClassifier_DL_erm. For example, the implementation of IRM algorithm can be found at algorithm/dl_irm.py and config/dl_irm.yaml.
For both traditional ML and DL algorithms, it is also possible to start from the plain DepressionDetectionAlgorithmBase and DepressionDetectionClassifierBase.
How to add a new dataset
To include a new dataset in the pipeline, it needs to do the following steps:
- Define the name of the new dataset with the template
[group name]_[dataset NO in the group], e.g.,ABC_1. - Following the same structure as other dataset folders in
data_raw, the new dataset folder (e.g.,,ABC_1) needs to contain three subfolders. Please refer todata_raw/README.mdfor more details:FeatureData: a csv filerapids.csvindexed bypidanddatefor feature data, and separate files[data_type].csvindexed bypidanddatefor each data type. Each row is a feature vector of a subject at a given date. Example columns: [pid,date,feature1,feature2...]. Columns include all sensor features of Phone Location, Phone Screen, Calls, Bluetooth, Fitbit Steps, and Fitbit Sleep from RAPIDS toolkit3.SurveyData: csv files indexed bypidanddatefor label data. For depression detection, there are two files:dep_weekly.csvanddep_endterm.csv. For other tasks, there are three files:pre.csv,post.csv, andema.csv.ParticipantsInfoData: a csv fileplatform.csvindexed bypidfor data collection device platform (i.e., iOS or Android). Example columns of the file: [pid,platform].
- Register the new path in
data/data_factory.pyby adding new key-value pairs in the following dictionaries:feature_folder,survey_folder, anddevice_info_folder(e.g., adding{"ABC": {1: ...}}). - Register the new dataset key into the
config/global_config.yamlintoglobal_config["all"]["ds_keys"](e.g., appending"ABC_1").
How to add a new modeling target
Our current platform only supports binary classification tasks. Future work will be needed to extend to multi-classification and regression tasks. To build a model for a new target other than depression detection, it needs to do the following steps:
- Pick a column in either
ema.csv, orpost.csv(seedata_raw/README.mdfor more details) as the target name. Note that the picked column needs to be consistent across all datasets defined inconfig/global_config.yaml. A column inpre.csvwould also work as long as the date can be handled correctly. HereUCLA_10items_POSTfrompost.csvis used as an example, a metric measuring loneliness. - Define the binary label for the target in
data/data_factory.py'sthreshold_book. A simple threshold based method is used to add akey:valuepair to thethreshold_book, wherekeyis the target name andvalueis a dionctionary{"threshold_as_false": th1, "threshold_as_true":th2}(note thatth1!=th2). For example, forUCLA_10items_POST, scores <= 24 will be defined asFalse, and scores >= 25 will beTrue. This corresponds to adding the followingkey:valuepair to thethreshold_book:"UCLA_10items_POST": {"threshold_as_false": 24, "threshold_as_true":25}. - Define it in the
config/global_config.yamlto involve it in the pipeline. Replaceglobal_config["all"]["prediction_tasks"]to be[the new target]. Continuing the example, it will be["UCLA_10items_POST"].
Contributing
This project adopts Apache License 2.0 and welcomes contributions and suggestions. We look forward to researchers extending the platform with new algorithms and datasets.
Citation
If you find the dataset/codebase helpful in your research, please cite the following paper.
@inproceedings{
xu2022globem_neurips,
title={{GLOBEM} Dataset: Multi-Year Datasets for Longitudinal Human Behavior Modeling Generalization},
author={Xuhai Xu and Han Zhang and Yasaman S Sefidgar and Yiyi Ren and Xin Liu and Woosuk Seo and Jennifer Brown and Kevin Scott Kuehn and Mike A Merrill and Paula S Nurius and Shwetak Patel and Tim Althoff and Margaret E Morris and Eve A. Riskin and Jennifer Mankoff and Anind Dey},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://arxiv.org/abs/2211.02733}
}
@article{
xu2022globem_imwut,
title = {{GLOBEM}: {Cross}-{Dataset} {Generalization} of {Longitudinal} {Human} {Behavior} {Modeling}},
volume = {6},
number = {4},
journal = {Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies},
author = {Xu, Xuhai and Liu, Xin and Zhang, Han and Wang, Weichen and Nepal, Subgiya and Kuehn, Kevin S and Huckins, Jeremy and Morris, Margaret E and Nurius, Paula S and Riskin, Eve A and Patel, Shwetak and Althoff, Tim and Campell, Andrew and Dey, Anind K and Mankoff, Jennifer},
year = {2022}
}
Footnotes
-
Feature overlap is maximized during the implementation. For features that are not consistently available, they are excluded to ensure compatibility. ↩
-
We use sample data for testing purpose. ↩
-
Assuming that the new dataset was collected using the AWARE framework so that it can be processed by RAPIDS directly. Otherwise, additional data transformation is needed before applying RAPIDS. ↩