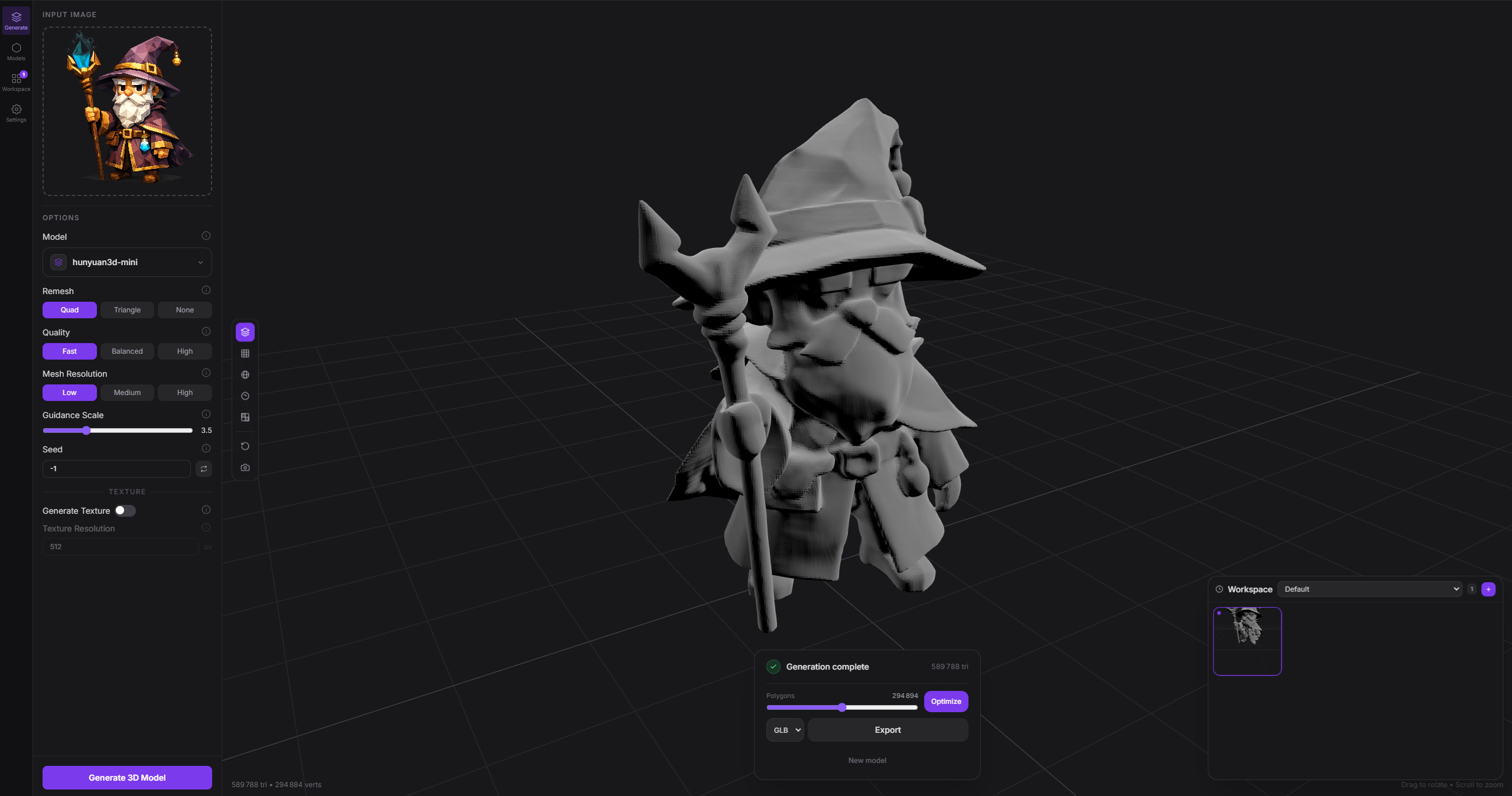
一张图进去,3D 模型出来——这个开源桌面应用全程跑在本地 GPU
图片转 3D 模型通常有两条路:用 Blender / ZBrush 手动建,或者上传到在线 AI 服务处理。Modly 是第三条——本地桌面应用,GPU 跑推理,不联网,代码完全开源。
技术栈是 Electron + React + TypeScript 做前端界面,Python FastAPI 做推理后端,C++ 和 CUDA 负责 GPU 加速。目前支持 Windows 和 Linux,macOS 尚未发布。
图片转 3D 的完整流水线
上传一张图片后,后端会依次经过 5 个阶段,前端通过轮询 /generate/status/{job_id} 获取进度:
| 阶段 | 进度 | 处理内容 |
|---|---|---|
| 背景移除 | 5% | rembg(ONNX 加速)抠图,得到透明背景 RGBA 图 |
| 形状生成 | 12–70% | Hunyuan3DDiTFlowMatchingPipeline 生成 3D 网格 |
| 纹理生成 | 72–83% | 可选,Hunyuan3D Paint 模型为网格上色 |
| 网格优化 | 85% | Quadric Edge Collapse 四边形坍缩,减少顶点数 |
| 导出 | 96% | 输出 GLB(二进制 glTF 2.0)格式 |
前端用 multipart/form-data 发起请求:
POST /generate/from-image
image: <binary>
model_id: "hunyuan3d-mini"
num_inference_steps: 30
octree_resolution: 380
guidance_scale: 5.5
seed: -1
enable_texture: false
vertex_count: 10000生成完成后前端用 Three.js + @react-three/fiber 直接预览 GLB,不需要打开外部软件。
核心参数说明
生成质量主要由以下参数控制:
| 参数 | 范围 | 默认 | 作用 |
|---|---|---|---|
num_inference_steps | 10–50 | 30 | 扩散步数,越高质量越好、耗时越长 |
octree_resolution | 256–512 | 380 | 网格分辨率,越高细节越多 |
guidance_scale | 1.0–10.0 | 5.5 | 图像保真度,越高越贴近输入图片 |
seed | -1 或正整数 | -1 | -1 随机,指定数值可复现结果 |
vertex_count | — | 10000 | 网格简化目标顶点数 |
官方扩展中 num_inference_steps 提供三档预设:Fast (10步)、Balanced (30步)、High (50步),这些选项由扩展的 params_schema 定义,前端动态渲染成 UI 控件。
扩展系统:如何接入自定义模型
Modly 的模型层完全插件化,每个扩展是一个 GitHub 仓库,包含两个核心文件:
manifest.json:声明模型元数据、变体列表和参数定义
{
"id": "hunyuan3d-mini",
"generator_class": "Hunyuan3DMiniGenerator",
"hf_repo": "tencent/Hunyuan3D-2mini",
"models": [
{ "id": "hunyuan3d-mini", "name": "Standard" },
{ "id": "hunyuan3d-mini-turbo", "name": "Turbo" },
{ "id": "hunyuan3d-mini-fast", "name": "Fast" }
],
"params_schema": [
{
"id": "num_inference_steps",
"type": "select",
"default": 30,
"options": [
{ "value": 10, "label": "Fast (10 steps)" },
{ "value": 30, "label": "Balanced (30 steps)" },
{ "value": 50, "label": "High (50 steps)" }
]
}
]
}generator.py:继承 BaseGenerator 抽象基类,实现核心方法
class BaseGenerator(ABC):
MODEL_ID: str = ""
VRAM_GB: int = 0 # 最低显存需求(GB)
def is_downloaded(self) -> bool: ... # 检查权重文件是否存在
def load(self) -> None: ... # 加载模型到 GPU/CPU
def generate(
self,
image_bytes: bytes,
params: dict,
progress_cb: Callable[[int, str], None] = None
) -> Path: ... # 返回生成的 .glb 路径
def unload(self) -> None: ... # 释放显存扩展被克隆到 ~/.modly/extensions/ 后,应用启动时自动扫描并加载。官方扩展带有 RSA-256 签名验证,第三方扩展加载时会显示未签名警告,被篡改的扩展直接拒绝加载。
模型权重从 Hugging Face 下载,存储在 ~/.modly/models/,生成的 GLB 文件保存在 ~/.modly/workspace/。
硬件要求
Modly 使用 CUDA 加速,主要针对 NVIDIA 显卡。以 Hunyuan3D 2 Mini 为例:
- 最低显存:6GB
- 推理精度:float16(CUDA)/ float32(CPU 回退)
- 模型参数量:0.6B(轻量级)
Standard / Turbo / Fast 三个变体对应不同的生成速度和显存占用,可以根据硬件情况选择。
安装
直接下载(推荐)
从 Releases 页面 (opens in a new tab) 下载安装包,Windows 用 .exe,Linux 运行 ./launcher.sh。
从源码启动
npm install
cd api
python -m venv .venv
# Windows: .venv\Scripts\activate / Linux: source .venv/bin/activate
pip install -r requirements.txt
npm run dev启动后在 Models 页面安装扩展(输入 GitHub 仓库地址),下载模型权重后即可使用。
写在最后
Modly 目前还处于早期,官方只有 Hunyuan3D 2 Mini 这一个扩展,macOS 也还没支持。
架构上有两个地方值得关注:一是 Electron + FastAPI 的进程通信模式(localhost:8765)——这是在桌面端把 Python AI 推理和前端界面解耦的常见做法;二是扩展系统的设计,BaseGenerator 的抽象接口定义清晰,如果想把 TripoSR、InstantMesh 这类其他开源 3D 生成模型接进来,按规范实现一个 generator.py 就够了。
GitHub:https://github.com/lightningpixel/modly (opens in a new tab)