模型文件太大、帧率莫名其妙低?大概率是这个问题
一个 3D 模型从建模工具里导出,到最终在 GPU 上渲染出来,中间经历的不只是"传数据"这一步。GPU 有自己的流水线,每个阶段都有各自的效率瓶颈。如果数据在进入 GPU 之前没有专门处理过,很容易在某个环节卡住,帧率就掉下来了。
meshoptimizer 是一个专门解决这件事的 C++ 库(7600+ stars),作者 Arseny Kapoulkine 在游戏工业界做了十几年图形引擎。库的核心思路是:针对 GPU 渲染管线里每一个会拖慢速度的地方,分别提供对应的优化算法。
GPU 在读网格数据时做什么
GPU 渲染三角形网格,背后涉及三个硬件阶段,每个阶段的效率都由数据的排列方式决定:
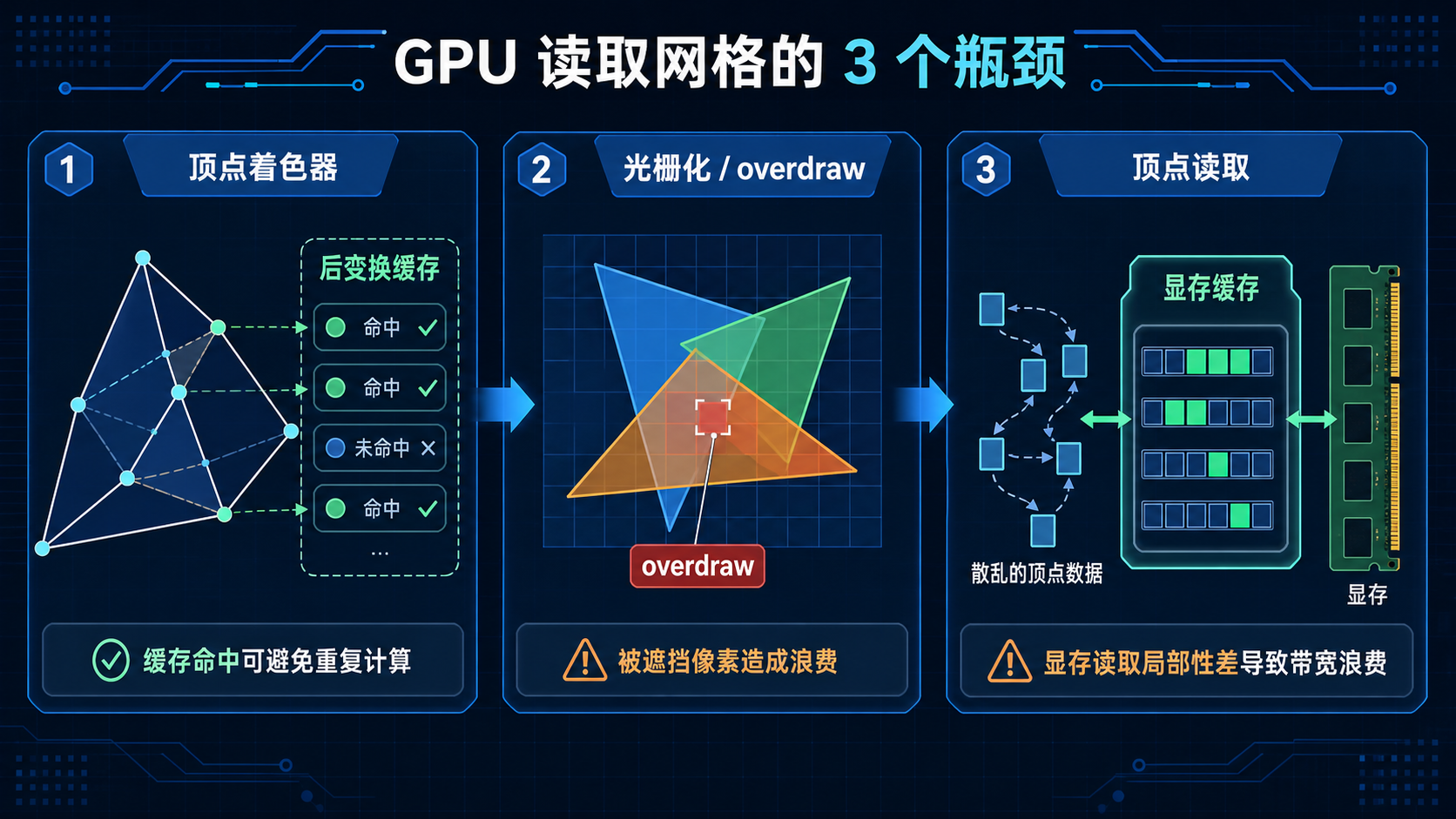
顶点着色器阶段:GPU 对每个顶点跑一次顶点着色器,但相邻三角形共享的顶点可以复用。GPU 内部有个"后变换缓存"(post-transform cache),存最近处理过的顶点结果。如果顶点在索引缓冲里的顺序是随机的,缓存命中率就很低,大量顶点会被重复计算。
光栅化阶段:同一个像素可能被多个三角形覆盖,GPU 会对每个像素跑深度测试,通过了才执行像素着色器。如果网格里不透明的三角形把被遮挡的三角形排在前面,这些被遮挡的像素就白白跑了一遍着色器——这叫 overdraw。
顶点读取阶段:顶点数据从显存读进来,走显存缓存。如果顶点着色器需要的顶点在显存里散得很开,缓存命中率低,就得多次跑显存。
meshoptimizer 的 "core pipeline" 对这三个阶段分别有对应的算法,而且要按顺序跑:
索引生成 → 顶点缓存优化 → overdraw 优化 → 顶点读取优化 → 顶点量化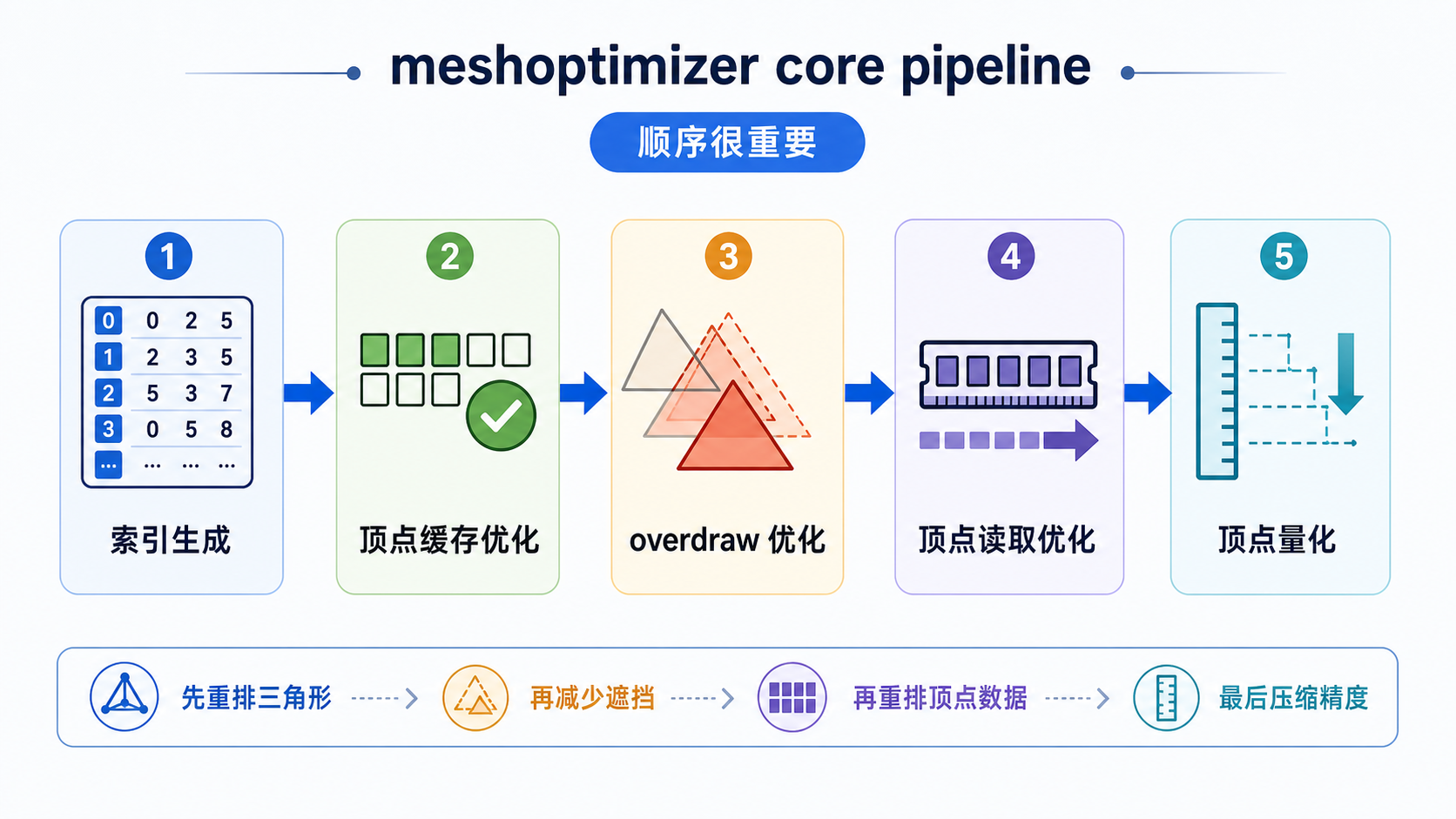
meshoptimizer 的做法
顶点缓存优化是第一步,也是效果最显著的一步。调用方式很直接:
meshopt_optimizeVertexCache(indices, indices, index_count, vertex_count);这一步会重排三角形顺序,让相邻三角形共用顶点的概率最大化。库里用的是自适应算法,不针对特定 GPU 架构的缓存大小做假设,在不同硬件上都能给出不错的结果。如果要针对固定大小 FIFO 缓存专门优化,也有 meshopt_optimizeVertexCacheFifo,速度快约 2 倍,适合需要快速迭代内容的场景。
overdraw 优化在顶点缓存优化之后跑:
meshopt_optimizeOverdraw(indices, indices, index_count, &vertices[0].x, vertex_count, sizeof(Vertex), 1.05f);最后那个参数 1.05f 是阈值——算法可以为了减少 overdraw 牺牲一些顶点缓存命中率,但最多只能差 5%。这个取舍是必要的,因为两个目标有时候互相冲突。
顶点读取优化在最后跑,把顶点在顶点缓冲里的顺序改成"按使用顺序排":
meshopt_optimizeVertexFetch(vertices, indices, index_count, vertices, vertex_count, sizeof(Vertex));索引压缩:从 6 字节到 1.2 字节
网格数据在存储和传输时,原始的 16-bit 索引数据每个三角形要占 6 字节(3 个索引 × 2 字节)。meshoptimizer 提供了一套专门的编解码器,能把这个降到 1-1.2 字节/三角形——前提是索引数据已经经过顶点缓存优化。

// 编码
std::vector<unsigned char> ibuf(meshopt_encodeIndexBufferBound(index_count, vertex_count));
ibuf.resize(meshopt_encodeIndexBuffer(&ibuf[0], ibuf.size(), indices, index_count));
// 解码
meshopt_decodeIndexBuffer(indices, index_count, &ibuf[0], ibuf.size());解码器经过了专门的性能优化,在现代桌面 CPU 上跑 3-6 GB/s,可以直接写入 write-combined 内存。顶点数据的编解码也有类似的方案,压缩比通常在 2-4x 之间。
这套编解码格式被标准化为 glTF 扩展 EXT_meshopt_compression,意味着压缩后的文件可以在任何支持这个扩展的加载器里直接用。
gltfpack:对 Three.js 开发者最直接有用的工具
如果你用 Three.js 或 Babylon.js,gltfpack 是最直接的使用入口。它是一个命令行工具,读取 .gltf、.glb 或 .obj 文件,自动跑上面的所有优化,输出可以直接给渲染器用的文件:
# 基础优化:顶点缓存、量化、合并 mesh
gltfpack -i scene.gltf -o scene.glb
# 开启压缩(需要解码器支持)
gltfpack -c -i scene.gltf -o scene.glb
# 更高压缩率
gltfpack -cc -i scene.gltf -o scene.glb
# 同时压缩纹理(输出 KTX2 格式)
gltfpack -cc -tc -i scene.gltf -o scene.glb
# 网格简化(保留 50% 三角形)
gltfpack -si 0.5 -i scene.gltf -o scene.glbgltfpack 做的事情不止压缩:它会合并静态 mesh 来减少 draw call 数量,重采样动画数据来缩小动画体积,裁剪掉场景树里冗余的节点。
在 Three.js 里加载压缩后的文件(需要 r122+):
import { MeshoptDecoder } from 'three/examples/jsm/libs/meshopt_decoder.module.js';
const loader = new GLTFLoader();
loader.setMeshoptDecoder(MeshoptDecoder);
loader.load('scene.glb', (gltf) => {
scene.add(gltf.scene);
});
Babylon.js 5.0+ 不需要额外配置,直接加载。
写在最后
meshoptimizer 的整套算法都在 C/C++ 头文件里,嵌入 native 项目只需要加源文件,不需要修改构建配置。JavaScript 版本(meshoptimizer npm 包)提供了部分算法的 WebAssembly 实现,可以在浏览器里做运行时处理,但用途更多是工具链集成,不是每帧都跑的逻辑。
对于 Web 3D 场景,最实用的路径是把 gltfpack 加进构建流程:原始模型走一遍 gltfpack,输出压缩后的 glb,然后用 MeshoptDecoder 在运行时解码。压缩 glb 文件比原始文件小很多,解码速度又足够快,对首屏加载时间有明显帮助。
对于 draw call 数量多的复杂场景,gltfpack 的 mesh 合并(-mi)和场景树裁剪也值得试,它能在不改代码的情况下减少不少渲染批次。
库本身不包含渲染 API 封装,也没有处理动态变形或程序化生成几何体的工具,这些场景需要在应用层另行处理。
GitHub:https://github.com/zeux/meshoptimizer (opens in a new tab)